Abstract
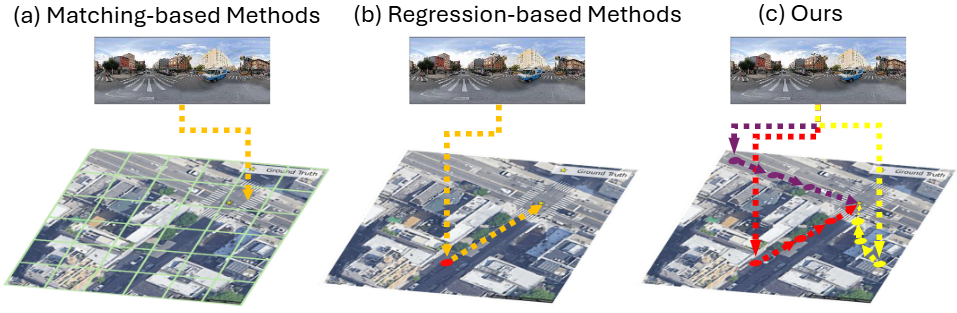
Accurate and fast localization is vital for safe autonomous navigation in GPS-denied areas. Fine-Grained Cross-View Geolocalization (FG-CVG) aims to estimate the precise 2-Degree-of-Freedom (2-DoF) location of a ground image relative to a satellite image. However, current methods force a difficult trade-off, with high-accuracy models being slow for real-time use. In this paper, we introduce GeoFlow, a new approach that offers a lightweight and highly efficient framework that breaks this accuracy-speed trade-off. Our technique learns a direct probabilistic mapping, predicting the displacement (in distance and direction) required to correct any given location hypothesis. This is complemented by our novel inference algorithm, Iterative Refinement Sampling (IRS). Instead of trusting a single prediction, IRS refines a population of hypotheses, allowing them to iteratively ‘flow’ from random starting points to a robust, converged consensus. Even its iterative nature, this approach offers flexible inference-time scaling, allowing a direct trade-off between performance and computation without any re-training. Experiments on the KITTI and VIGOR datasets show that GeoFlow achieves state-of-the-art efficiency, running at real-time speeds of 29 FPS while maintaining competitive localization accuracy. This work opens a new path for the development of practical real-time geolocalization systems.
Method
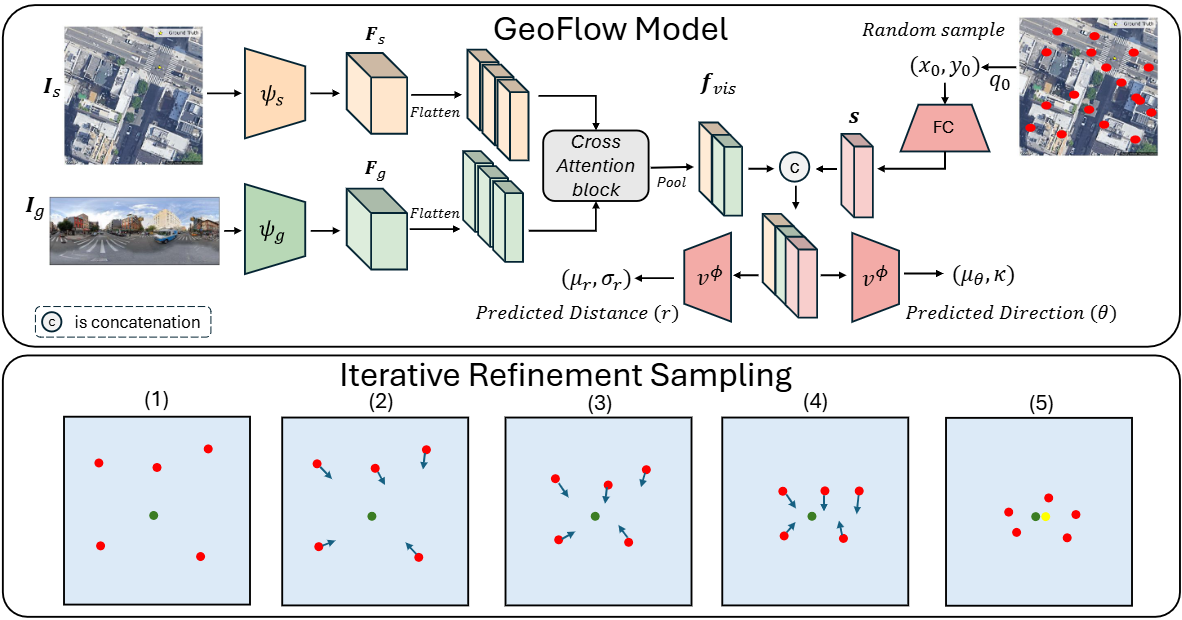
The top panel illustrates the architecture of our proposed GeoFlow. Ground () and satellite () features are extracted by and , then flattened, positionally encoded, and fused by a Cross-Attention block to produce a single visual representation, . Separately, an initial location point is passed through a fully connected layer (FC). This point embedding is concatenated with to form the joint representation . Finally, two regression heads () predict the parameters for the probabilistic displacement: distance and direction . The bottom panel illustrates our Iterative Refinement Sampling (IRS) algorithm. (1) The process starts with randomly sampled hypotheses (red dots); the green dot represents the ground truth location. (2–4) In each round, our model predicts the displacement (blue arrows) for all hypotheses, which are then updated and iteratively converge toward the target. (5) After rounds, the final robust location (yellow dot) is computed as the mean of the entire converged population.
Results
We report localization error (Mean/Median, m), lateral/longitudinal recall (R@1m/R@5m, %), and inference speed (FPS) for both Same-Area and Cross-Area splits. Best results are in bold.
Method | Efficiency | Same-area | Cross-area | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FPS | Loc. (m) | Lateral (%) | Long. (%) | Loc. (m) | Lateral (%) | Long. (%) | |||||||
| Mean | Median | R@1m | R@5m | R@1m | R@5m | Mean | Median | R@1m | R@5m | R@1m | R@5m | ||
GGCVT | 4.17 | – | – | 76.44 | 98.89 | 23.54 | 62.18 | – | – | 57.72 | 91.16 | 14.15 | 45.00 |
CCVPE | 24.00 | 1.22 | 0.62 | 97.35 | 99.71 | 77.13 | 97.16 | 9.16 | 3.33 | 44.06 | 90.23 | 23.08 | 64.31 |
HC-Net | 25.00 | 0.80 | 0.50 | 99.01 | 99.73 | 92.20 | 99.25 | 8.47 | 4.57 | 75.00 | 97.76 | 58.93 | 76.46 |
DenseFlow | 7.30 | 1.48 | 0.47 | 95.47 | 99.79 | 87.89 | 94.78 | 7.97 | 3.52 | 54.19 | 91.74 | 23.10 | 61.75 |
FG | 4.20 | 0.75 | 0.52 | 99.73 | 100.00 | 86.99 | 98.75 | 7.45 | 4.03 | 89.46 | 99.80 | 12.42 | 55.73 |
GeoFlow (Ours) | 29.49 | 0.98 | 0.68 | 96.85 | 99.68 | 74.05 | 98.75 | 8.42 | 5.60 | 36.36 | 83.85 | 14.76 | 52.51 |
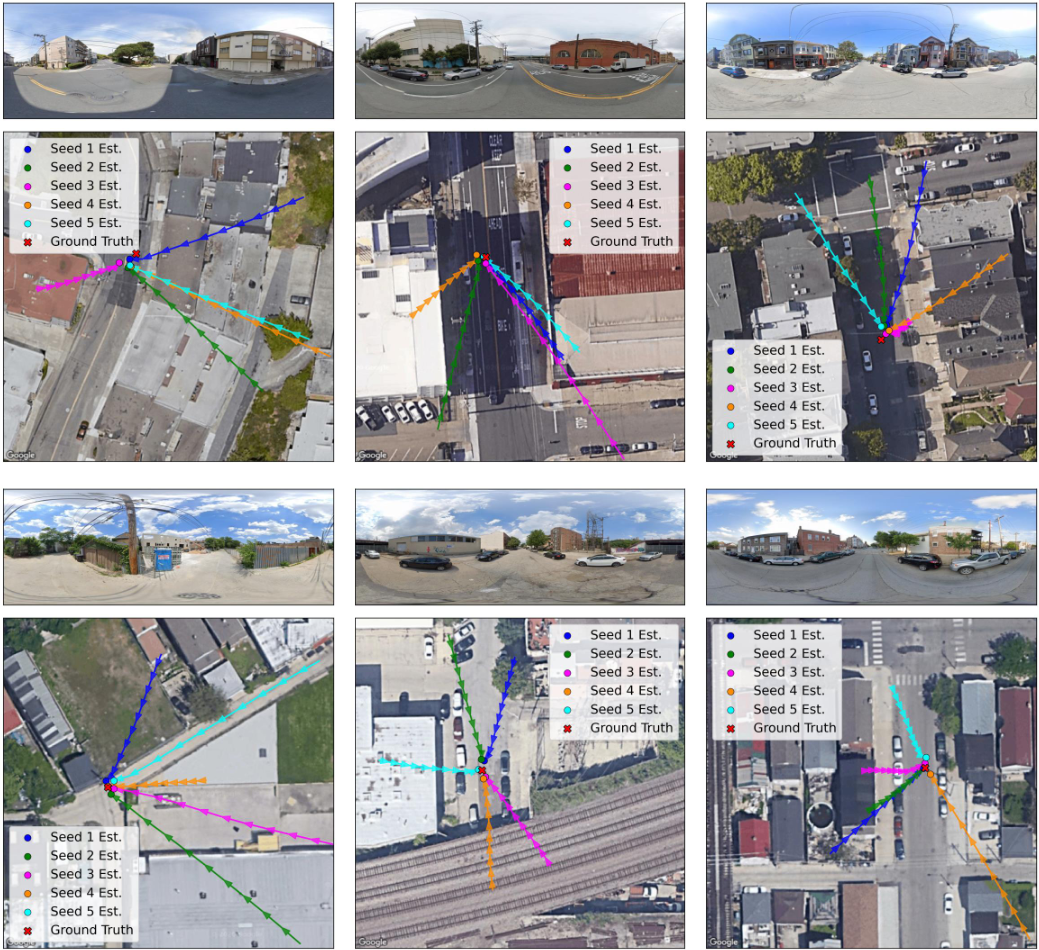
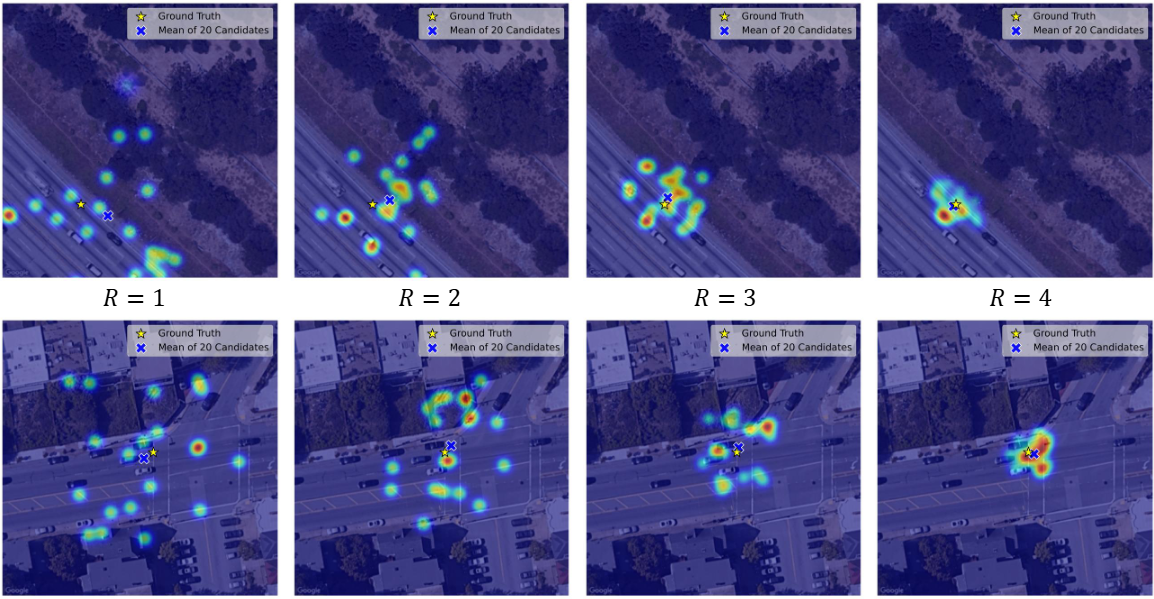
Ablations (KITTI Cross-Area)
Our inference is controlled by two inference-time knobs (no retraining required):
- : number of initial location hypotheses (random seeds) sampled at the start.
- : number of refinement rounds applied to all hypotheses.
Increasing improves robustness (more hypotheses), while increasing improves convergence (more refinement), at the cost of lower FPS.
Impact of refinement rounds ()
| Rounds () | Mean (m) | Median (m) | Speed (FPS) |
|---|---|---|---|
| 1 | 10.69 | 9.95 | 32.55 |
| 3 | 8.47 | 5.88 | 31.23 |
| 5 | 8.42 | 5.60 | 29.49 |
| 10 | 8.41 | 5.59 | 26.23 |
Impact of initial seeds ()
| Seeds () | Mean (m) | Median (m) | Speed (FPS) |
|---|---|---|---|
| 1 | 8.58 | 5.75 | 30.70 |
| 5 | 8.49 | 5.66 | 30.05 |
| 10 | 8.42 | 5.60 | 29.49 |
| 20 | 8.41 | 5.60 | 28.08 |
Efficiency
Unified efficiency comparison across representative FG-CVG methods. GeoFlow is designed for practical deployment on resource-constrained and edge devices, prioritizing low compute and memory footprint.
| Model | GFLOPs | VRAM | Inference time | FPS |
|---|---|---|---|---|
| CCVPE | 31.18 | 4730 MiB | 41.7 ms | 24.0 |
| HC-Net | 11.56 | 1900 MiB | 40.0 ms | 25.0 |
| GeoFlow | 7.65 | 686 MiB | 26.0 ms | 29.5 |
| Gain (vs HC-Net) | -34% | -64% | -35% | +18% |
Citation
@InProceedings{Abu_Lehyeh_2026_CVPR, author = {Abu Lehyeh, Ayesh and Zhang, Xiaohan and Arrabi, Ahmad and Sultani, Waqas and Chen, Chen and Wshah, Safwan}, title = {GeoFlow: Real-Time Fine-Grained Cross-View Geolocalization via Iterative Flow Prediction}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, month = {June}, year = {2026}, pages = {5369-5378}}